Recap
目標:判斷該不該給一個用戶核發信用卡
 source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/01u_handout.pdf p.21
source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/01u_handout.pdf p.21
Perceptron Hypothesis Set
對每一筆 x 我們都計算一筆權重分數,然後根據有沒有大於 threshold 來通過或拒絕,換成數學式如下:
h(x)=sign((∑i=1dwixi)− threshold),h∈H
如此一來,輸出 Y 就變成只有 1 (good) 和 -1 (bad)
用矩陣表達
我們可以將上面的式子化成矩陣來表示,透過將 threshold 視為權重的一部份(w0),並將 x0 設為 1,就能得到下列的數學式:
 source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/02u_handout.pdf p.4
source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/02u_handout.pdf p.4
Notation Conventions
- traning examples D size: n=1,2,⋯,N
- features size: i=0,1,⋯,d
- x=(x0,x1,⋯,xd): an input vector
- xn=(xn,1,xn,2,⋯,xn,d): the n-th vector in D
- w 和 wt 同理
從空間視角來看
如果我們放在空間中來看:
- featrues x: points in Rd
- labels y: +1 或 -1 (用顏色表示)
- perceptron h: Rd 中的超平面 (可以將空間一分為二的邊界)
我們的目的就是找到一個 h 可以很剛好地把 y=h(x) 不同的 x 們分開
y 只有兩種,所以 perceptrons 其實就是 linear binary classifiers
Perceptron Learning Algorithm (PLA)
如何在 H (所有可能的 perceptrons) 裡面找到一個 g,讓這個 g 和 f (理想中的完美函數) 盡可能地接近?
註: 由於 perceptron gt 內的需要設定的數值只有 wt,因此接下來直接用 wt 來表示 gt
PLA 流程
從 w0 (零向量) 開始,t=0,1,⋯
第一步: 找 mistake
使用 wt 進行分類,找到一個 mistake (xt,yt),也就是
sign(wtTxt)=yt
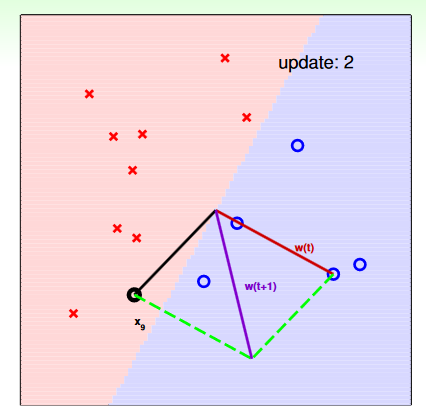
第二步: 更新 w
如下圖,如果 yt=+1,但 sign 的結果是 -1,即 wtTxt<0,也就是說 w 和 x 的夾角大於 90 度,分類錯了,因此我們必須將 w 旋轉讓夾角小於 90。更新的方法就是直接做向量的合成:
wt+1←wt+ytxt
w 實際上表示的是 g (分類線) 的法向量,因此如果 x 和 w 的夾角小於 90 度,也就是 wtTxt>0,則分類為 +1,反之亦然。
 source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/02u_handout.pdf p.13
source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/02u_handout.pdf p.13
就這樣直到找不到 mistake 為止
sign = 0 怎麼辦
當 sign = 0 的時候,實際上有許多種處理方法,每個人都有自己的慣例:
- 將 sign(0) 視為 -1
- 將 sign(0) 視為 +1
- 直接更新
實際上除了 w0 會出現這種情況外,其餘要發生 sign = 0 的機會不高
Cyclic PLA
上面的流程還有問題沒有解決: 怎麼找 mistake? 如果有很多個 mistake 怎麼辦?
實務上,常用的方法是遍歷每個點,從 x1 到 xn,遇到 mistake 就更新,直到遍歷了每個點都沒有找到 mistake 為止,這種方法稱為 cyclic PLA。
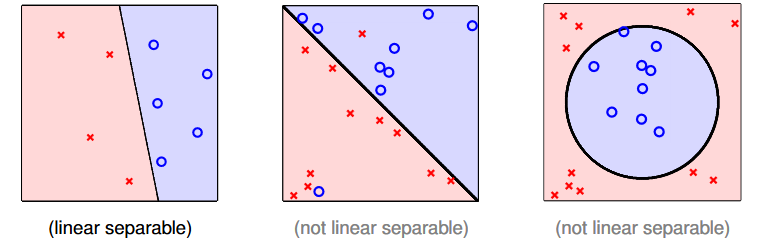
Linear Separability
PLA 基本上只適用於可以線性二分的 D,如下圖所示:
 source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/02u_handout.pdf p.15
source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/02u_handout.pdf p.15
證明 PLA 會停止
假設 D linear separable,也就是說一定有一個 wf 使得 yn=sign(wfTxn)
因為可以完美分類,代表每一個 xn 和 wf 的夾角都大於 0:
ytwfTxt≥minnynwfTxn>0
然後,我們可以從更新的式子中推出,每一次更新,wt 都會更靠近 wf (夾角越小):
wt+1wfTwt+1=wt+ytxt=wfT(wt+ytxt)≥wfTwt+ytwfTxt>wfTwt+0
w 的(長度)成長速率
wt changed only when sign(wtTxt)=yt⟺ytwtTxt≤0
因此我們可以推出,w 的成長幅度不會超過用來更新的 x 的長度,也不會超過最長的 x 的長度:
∥wt+1∥2=∥wt+ytxt∥2=∥wt∥2+2ytwtTxt+∥ytxt∥2≤∥wt∥2+∥ytxt∥2≤∥wt∥2+nmax∥ynxn∥2
PLA Bound
從上面兩個推導可以知道
- 內積的成長速率快: wfTwt+1≥wfTwt+minnynwfTxn
藍色替換成 ρ⋅∥wf∥
- 長度的成長速率慢: ∥wt+1∥2≤∥wt∥2+maxn∥xn∥2
紅色替換成 R2
在 T 次更新後
- wfTwT≥ w0Tw0+T⋅ρ⋅∥wf∥=T⋅ρ⋅∥wf∥
- ∥wT∥2≤ ∥w0∥2+T⋅R2=T⋅R2
接著就可以發現 wf 和 wT 的 cos 夾角會有 lower bound,而且更新次數 T 有 upper bound
∥wf∥wfT∥wT∥wT≥∥wf∥⋅T⋅RT⋅ρ⋅∥wf∥⟹T≤(ρR)2
Overview
優點: 簡單、快速、適用於任何維度
缺點:
- D 需要 linear separable (而且我們通常不會知道)
- 因為 ρ depends on wf,不能確定什麼時候會停 (雖然如果會停的話通常很快就會停)
PLA with noisy data
如果我們的 D 是有雜訊的 (不是 linear separable),我們或許可以讓 PLA 多一點容忍度,只要「大多數」的 x 都有符合 f(xn)=yn 就好,因此我們的目標就是找到 mistake 最少的那個 g 就好:
wg←argminw∑n=1N[[yn=sign(wTxn)]]
然而,這是一個 NP-hard 問題