Different Output Space
Binary Classification
是否核發信用卡、是否為詐騙郵件
Multiclass Classification
圖片裡是什麼水果
Multilabel Classification
圖片包含哪些水果、幫東西上(多個)標籤
Binary Relevance
將 multilabel classification 拆解成多個 binary classification 來實作
缺點是可能沒辦法找出 class 之間的關係 (isolation)、或是 yes 跟 no 的分布不均衡 (imbalanced)
Regression
從病歷看病患多久可以恢復、從天氣數據看明天溫度
or
(bounded regression)
Sophisicated Output
圖片生成、低畫質生成高畫質圖片
(width, height, channel)
不只是 multi-pixel regression,因為需要考慮 pixel 之間的關係
Different Data Label
Supervised Learning
每個 都有對應的 (label)
但是幫資料上 label 是非常耗費資源的事,因此出現了下面的許多不同方案
Unsupervised Learning
在不知道任何 label 的情況下學習
舉例來說我們想要幫文章分類,但我們還沒分類之前並不會知道有那些類別,因此用 unsupervised learning 就能在不設定類別的前提下學習,而我們可以透過演算法(或是人工)來尋找結果內的資料模式、關係,像是看到某幾筆資料在空間內分布特別接近,就可以把他們圈成同一個 cluster 並上同個 label。
- Clustering unsupervised multiclass classification,像是剛剛提到的幫文章分類
- Density Estimation unsupervised bounded regression,預測資料在範圍內的機率
- Outlier Detection extreme unsupervised binary classification,尋找不正常的資料
Semi-supervised Learning
unsupervised learning + some labeled data
本質上算 unsupervised,因為大部分的資料都還是 unlabel data,不過有少部分的 labeled data,因此在最後找資料模式的時候可以更容易幫其他沒有 label 的資料上 label,簡單來說就是透過少量 labeled data 來強化機器幫 unlabeled data 上 label 的準確度。舉例來說用部分的人臉資料來作人臉辨識、用部分的藥劑資料來預測新藥的療效。
下圖是用 supervised、semi-supervised、unsupervised 來幫硬幣分類的差異:
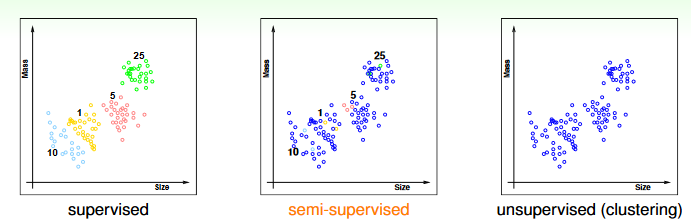 source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/03u_handout.pdf p.16
source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/03u_handout.pdf p.16
Self-supervised Learning
unsupervised learning + self-defined task(s)
是一種 pre-training,在執行 downstream task (真正想要機器學習的) 之前先讓機器自己生成一些 task,然後用這些 task 來訓練機器的某些能力 (通常是理解數據結構、特徵),藉此強化之後學習的效果。這裡的「自己生成」其實並不完全是機器自己設計 task,而是我們先透過原始數據 (unlabeled data) 的特性設計 task,然後機器會自己從 unlabeled data 內生成 labeled data,用這些 labeled data 來訓練自己。
舉例來說,我們想訓練 NLP 模型,則我們可以先設計一個克漏字 task:「讓機器隨機遮蔽句子中的某些詞,讓機器去預測這些詞是什麼」,由於答案其實就在原始資料內,因此機器可以自己生成目標來自己訓練,藉這個 task 機器可以學會各個詞之間的關係,讓之後的 downstream task (文本理解) 表現更好。
註: 上面的舉例來自於 BERT 架構的 Masked Language Model (MLM) 任務 https://arxiv.org/pdf/1810.04805
Weakly-supervised Learning
使用非真的標籤來學習,有幾種主要方法
- complementary label : 不用「蘋果」來當作標籤,而是用「不是香蕉」來當標籤
- partial label: 一個包含幾個真的 label 的集合
- noisy label : noisy version of true
- proportion label: 使用 的統計數據 (平均數之類的)
Reinforcement Learning
不告訴機器我們真正想要什麼,而是在對機器的學習結果給出一個「好壞分數」,讓機器修正自己。舉例來說我們想讓機器學打德撲, 是拿到的牌, (輸出) 是配牌策略,我們很難直接跟機器說明什麼策略是最好的,但是我們可以給 一個好壞分數 ,讓機器修正自己的策略來拿到更高的分數。
Staged-ML
以(舊的) GPT 為例:
- GPT-3:利用 self-supervised 訓練出的 pre-train model,給 2048 個 token 讓機器預測下一個 token 是什麼
- chatGPT: 在 GPT-3 之上,經過三個階段的訓練
- supervised (few-shot): 給予一些句子 (input),搭配人類決定的好答案 (label) → 訓練出一個可以從句子生成回答的 fine-tune GPT-3
- supervised (ranking): 給予一些句子 (inpt),產生數個答案,然後讓人類幫這些答案以好壞排序 (label) → 訓練出一個能夠判斷回答好壞的 reward model
- reinforcement: 給予句子 (input),讓 fine-tune GPT-3 產生回答,並透過 reward model 給予分數,不斷重複訓練 這種多階段的 staged-ML 對於訓練大型模型非常重要
Different Protocol
Batch Learning
目前為止介紹的都算是 batch learning,全部的 data 都是已知的,一次利用全部的 data 去訓練
Online Learning
每一筆 data 都是分開的餵給模型來學習。
舉例來說,訓練一個詐騙郵件偵測的模型,當每收到一封信 ( 代表來的順序),模型會用現有的函數給出一個 ,用戶也會自己判斷這封信是否為詐騙郵件 (desired label ),然後透過 來更新 。
實際上 reinforcement 很常利用 online 的方式進行,因為如果一次將所有 input 餵給模型,並一次性的打了分數,那這樣模型只會修正一次,所以最好每一筆 input 都是分開的餵給模型並修正,這樣模型才能逐漸的進步。
Online + Batch for Real-World
實際上,很多現實的 ML 會使用混合的方式進行,以聊天機器人為例,每一次有用戶的 request,都會收集該用戶的 feedback 作為 desired label,但是每一次有 request 都更新 model 會很耗費資源,因此會一次性的收集可能一天、或是特定數量的 request 後,在利用 batch learning 來更新 model。
Active Learning
上面的 label 都是模型被動的接收,我們給什麼它就學什麼,那 active learning 就是讓模型會(透過人類設計的策略)主動「詢問」特定 的 ,這樣一來模型可以針對那些比較不容易回答的 進行學習。
Different Input Space
Concrete feature
的每個維度都是可以嚴格定義的物理上的數據,舉例來說,尺寸、大小等等。
Raw feature
假設我們今天想要做手寫辨識,每一張手寫圖片 實際上都只是一個 256 像素的圖片 (256 維的 vector),但每一個像素 (raw data) 只有簡單的物理定義,如果讓機器直接對每個像素學習可能有點難,因為單獨一個像素太簡單了不會對結果造成太多影響。實際上,機器應該要針對這 256 個像素組合出來的圖片去做學習,那我們應該怎麼去幫這個組合出來的東西做定義呢? 因此我們會需要透過一些方法將 raw data 的組合轉換成 concrete feature,像是 symmetry (圖片的對稱性)、density (黑點的密集度),再用這些 concrete feature 去做學習。
Abstract feature
假設我們有一堆 userid、itemid 的資料,但都不包含他們本身的資訊(user 的年齡、item 的類型等),就是純數字 id,也就是沒有任何 concrete feature,這些 userid、itemid 就算是 abstract feature。 如果我們想預測特定 userid 給特定 itemid 的 rating,因為沒有這些 data 根本沒有定義可言,那我們要怎麼從這些 id 得到 concrete feature 呢?
Deep Learning
將 raw/abstract feature 自動轉換成 concrete feature (當然這只是簡略的說法) 回到手寫辨識的問題,下面這個模型(由下往上看)會自動拆解出 (extraction) 圖片的筆畫、線條等,然後用這些 feature 去進一步找出更 concrete 的 feature,一層一層進行拆解、轉換,直到得到可以用的 concrete feature。
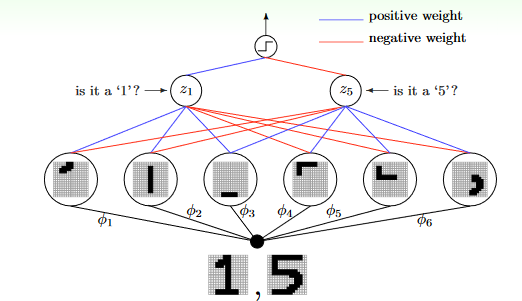 source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/03u_handout.pdf p.37
source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/03u_handout.pdf p.37