HTML Lecture 5- Training vs. Testing
Recap
統整一下前面的幾個章節:
對於 batch & supervised binary classification 的問題而言,g≈f⟺Eout≈0
而後者可以經由兩個階段來取得
- training: Ein≈0
- testing: Eout≈Ein
Trade-off on M
現在我們可以歸納出兩個問題:
- 如果確保 Ein 和 Eout 足夠接近?
- 如何讓 Ein 足夠小?
而這兩個問題都和 M (size of H) 有關:
- small M:
- Yes: 誤差 ≤2Mexp(⋯)
- No: 選擇太少
- large M:
我們要如何選擇剛好的 M 呢?
Effective Number of Lines
Union Bound is Over-estimated
在 Lecture 4,我們用了 union bound 的方法來計算誤差的 upper bound:
P[B1 or B1 or ⋯BM] ≤ P[B1]+P[B2]+⋯+P[BM]
其中 Bm 代表 bad event,也就是對於 hm 而言所有會導致 ∣Ein(hm)−Eout(hm)∣>ϵ 的 D。但是實際上當 h1≈h2 時,B1 和 B2 會有很多重疊的部分。為了把這些多算的重疊部分去掉,我們或許可以將類似的 h 歸在同一組。
How Many Lines Are There?
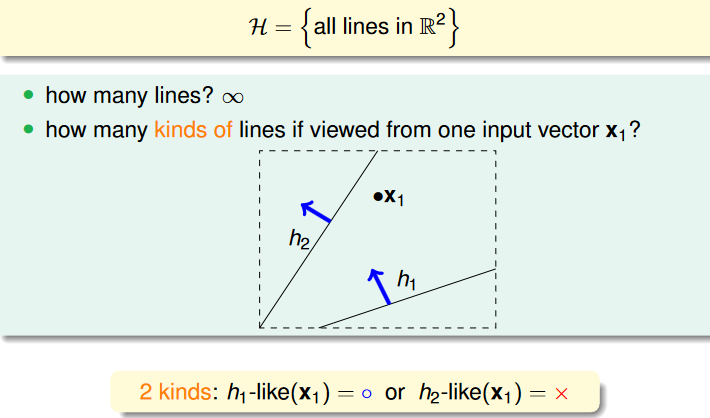 source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/05u_handout.pdf p.9
source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/05u_handout.pdf p.9
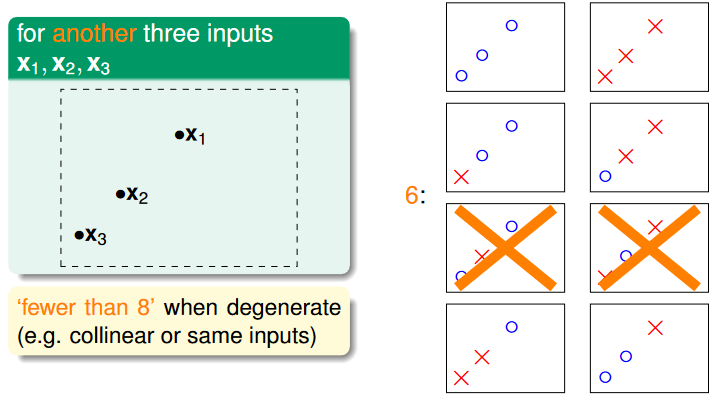 source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/05u_handout.pdf p.12
source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/05u_handout.pdf p.12
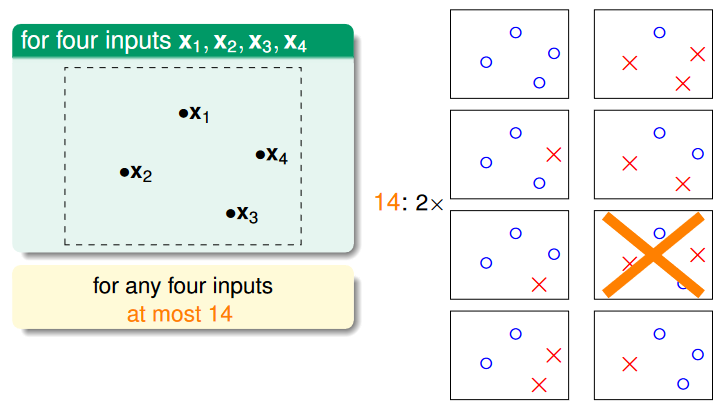 source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/05u_handout.pdf p.13
source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/05u_handout.pdf p.13
Effective Number of Lines
從上面可以發現,當有多個 inputs 的時候,我們必須考慮點重合在同一條線的情況,而我們將「N 個 inputs 最多能畫出來的線」叫做「effective number of lines」。
由於 effective number of lines 一定會小於等於 2N,因此我們有機會將 infinite 的 H 歸納成 finite 數量的 group of h,這樣就能夠用 effective number 來代替原本的 M (原本的公式):
P[∣Ein(g)−Eout(g)∣>ϵ]≤2⋅effective(N)⋅exp(−2ϵ2N)
Dichotomies
首先,我們將
h(x1,x2,⋯,xN)=(h(x1),h(x2),⋯,h(xN))∈{x,o}N
稱為 dichotomy,也就是限定 inputs 的 hypothesis。而 dichotomies
H(x1,x2,⋯,xN)={all dichotomy h(x1,x2,⋯,xN)}
則代表的就是所有對應 inputs 的 dichotomy 的集合。
所以我們可以用 dichotomies 的 大小 ∣H(x1,x2,⋯,xN)∣ (有 upper bound 2N) 來代替原本 H 的大小 M (可能是 infinte)。
Growth Function
由於 ∣H(x1,x2,⋯,xN)∣ 會跟 inputs 有關,所以我們計算時都會考慮最壞的情況,也就是取可能的最大值:
mH(N)=maxx1,⋯,xN∈X∣H(x1,x2,⋯,xN)∣
這個被叫做 growth function,也就是計算「當 input 成長時,dichotomies 的大小如何成長」。
計算 growth function 的例子:
 source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/05u_handout.pdf p.17
source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/05u_handout.pdf p.17
 source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/05u_handout.pdf p.18
source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/05u_handout.pdf p.18
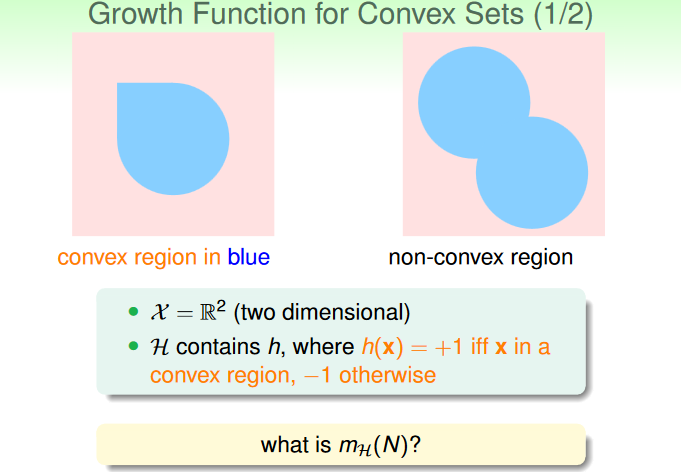 source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/05u_handout.pdf p.20
source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/05u_handout.pdf p.20
 source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/05u_handout.pdf p.21
source: https://www.csie.ntu.edu.tw/~htlin/course/ml24fall/doc/05u_handout.pdf p.21
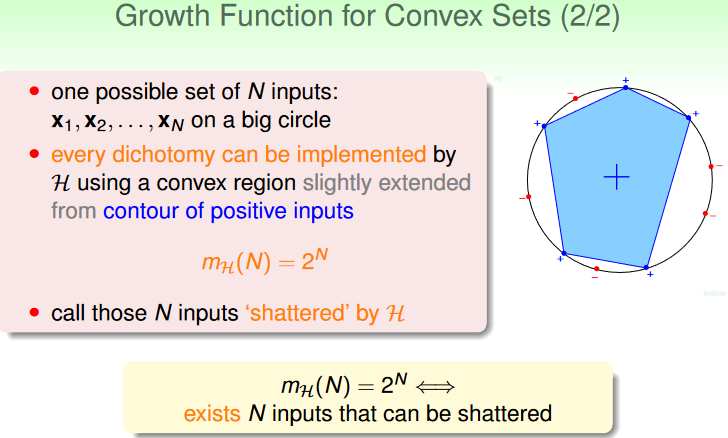
當 N 個 inputs 的任意組合 H 都有一個對應的 dichotomy 可以準確分類他們,也就是 mH(N)=2N,這時候我們就說這個 H 可以 shatter 這 N 個 inputs。
Break point
事實上,shatter 的情況是我們最不樂見的,這代表我們沒辦法「刪除」某些 input 組合來減少 dichotomy 的數量,因為每一種組合都可以被 H 分類。
現在來看看 2D perceptron 的例子:
- N=1: 可以被 shatter
- N=2: 部分情況可以被 shatter
- N=3: 部分情況可以被 shatter
- N=4: 沒有任何情況可以被 shatter (不管怎樣都只能找出 14<24 種 dichotomy)
當 k 個 inputs 的組合在任何情況下都不能被 shatter 時,也就是 mH(k)<2k,我們就說這個 k 是 break point,像是 2D perceptron 的 break point 就是 N=4,5,⋯,通常我們只會考慮最小的 break point。
統整前面提過的例子:
| | |
|---|
| positive rays | break point at 2 | mH(N)=N+1=O(N) |
| positive intervals | break point at 3 | mH(N)=21N2+21N+1=O(N2) |
| convex sets | no break point (不管 N 是多少都會被 shatter) | mH(N)=2N |
| 2D perceptrons | break point at 4 | mH(N)<2N in some cases |
可以發現當有 break point k 的時候,mH(N)=O(Nk−1),這部分的證明在 lecture 6 (教授說是 optional,所以我就沒有做筆記了)。